Explaining GPT Technology
How I expect to be using AI Large Language Models in the future.
Jun 2024 summary from Ethan Mollick:
the Jargon-Free Guide and this more technical (but remarkably clear) video, but the classic work by Wolfram is also good.
The Verge (Jul 2024) has an easy-to-understand summary of important AI Terminology.
Sample Exchange - Chinese Philosophy
LLMs for Dummies is a one-page summary with simpler language

For more, see this explainer from Ars Technica (Timothy B. Lee and Sean Trott) and this explainer from the FT (Madhumita Murgia).
Also see how Sarah Tavel frames pricing for AI tools as “work done” vs. per seat pricing as we’ve seen in traditional SaaS
OpenAI engineers wrote a short How does ChatGPT work. It’s an easy read, with diagrams, that summarizes the process of tokenization, embedding, multiplication of model weights, and sampling a prediction.
General Overview
Jonathan Shriftman’s The Building Blocks of Generative AI: A Beginners Guide to The Generative AI Infrastructure Stack is a lengthy overview of the various pieces of an end-to-end GPT-based system.
Image Generation
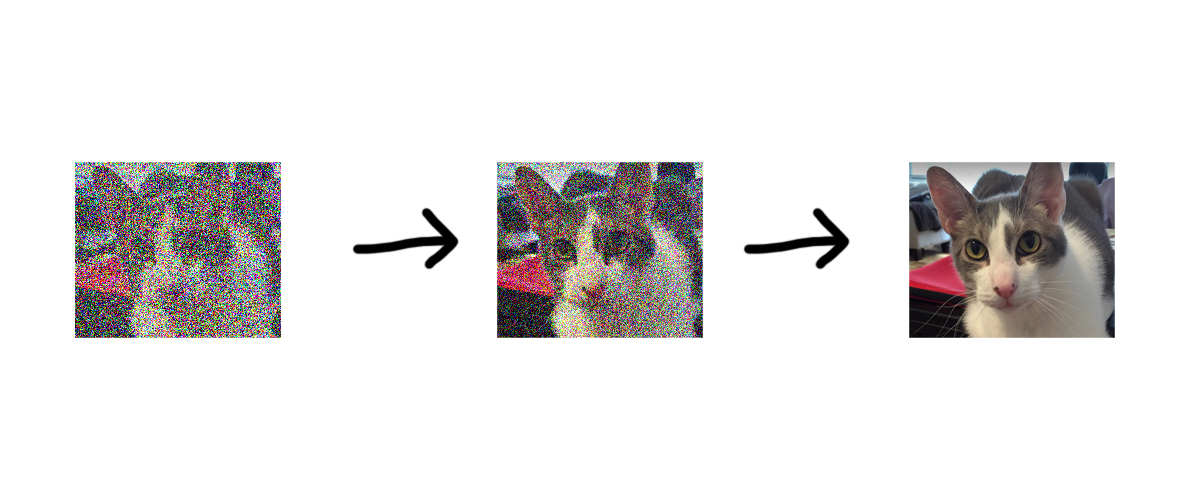
A very easy-to-follow description of how image-generation apps, like Dall-E or Midjourney, work: How AI Image Models Work
Explaining GPT Technology
Technical Terms
RNN: see Andrej Karpathy’s The Unreasonable Effectiveness of Recurrent Neural Networks a step-by-step description of RNNs (from 2015).
LoRA : Low Rank Adaptation
Microsoft Edward Hu:
freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on-par or better than fine-tuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency
Recent Developments Explained
Extremely lengthy rundown of recent LLM developments at Don’t Worry About the Vase
See especially #12: What GPT-4 Can Do and #14: What GPT-4 Can’t Do
What AI Can’t Do
What’s Next
Here’s a 72-page paper1 summarizing Challenges and Applications of Large Language Models
Kaddour et al. (2023)
and see Technology Review Mar 2024
In 2016, Chiyuan Zhang at MIT and colleagues at Google Brain published an influential paper titled “Understanding Deep Learning Requires Rethinking Generalization.” In 2021, five years later, they republished the paper, calling it “Understanding Deep Learning (Still) Requires Rethinking Generalization.” What about in 2024? “Kind of yes and no,” says Zhang. “There has been a lot of progress lately, though probably many more questions arise than get resolved.”